
I‘m pursuing a Ph.D. in Computer Science at Nanjing University, advised by Prof. Limin Wang and Prof. Tong Lu.
My research interests are General visual perception and human-computer and multimodal interaction system. I am focusing on general video understanding, egocentric vision perception and multimodal computing.
Previously, I worked on multimodal large model, Intern series, including InternVideo, InternVideo2, InternVL and InternVid. I also led the adaptation of the base model to the egocentric video understanding downstream and won 14 championships in two Ego4D/EgoVis contests.
Currently, I am working on frontier Vision-Language Models at NVIDIA, collaborating with Zhiding Yu, Guilin Liu, and other outstanding researchers on Project Eagle. Eagle2 is contributing to NVIDIA Cosmos Nemotron and NVIDIA Isaac GR00T N1. Eagle-2.5 is contributing to NVIDIA Cosmos Reasoner1 and NVIDIA Nemotron-H.
🔥 News
-
2025-09-18: 3 Neurips papers are accepted. They are Eagle2.5 for long-context VLM, EgoExoBench for egocentric-exocentric understanding benchmark, and EgoThinker for egocentric reasoning model and data.
-
2025-08-16: Vinci has been accepted by IMWUT 2025.
-
2025-06-05: We present a audio-visual counting benchmark, termed CG-AV-Counting, and a strong reasoning-based baseline model AV-Reasoner. The data and code are all released.
-
2025-05-29: Our paper EgoExoLearn has been selected as a deserved awardee of the Egocentric Vision (EgoVis) 2023/2024 Distinguished Paper Award.
-
2025-04-22: We present Eagle2.5, which boosts long-context visual-language capabilities, including long video understanding and multi-page document understanding.
-
2025-03-17: Eagle2 has been adopted by NVIDIA GEAR Team to develop robotic foundation model GR00T N1.
-
2025-01-22: 3 ICLR papers are accepted. They are CG-Bench for long video benchmark, EgoHOD for egocentric foundation model, and X-Gen for ego-exo cross-view video prediction.
-
2025-01-20: We present the frontier VLM, Eagle2 and the model weight has been released at huggingface.
-
2025-01-10: CG-Bench has been integrated into VlmevalKit.
-
2024-12-30: We present a real-time Embodied Smart Assistant, Vinci, based on Egocentric VLM. The code are at github
-
2024-12-16: We present the clue-grounded long video understanding benchmark CG-Bench and basic evaluation code at github.
-
2024-07-01: Our team wins Top-1 rankings in 7 tracks of 1st EgoVis ECCV2024 Challenge and the code are integrated into github.
-
2024-07-01: InternVideo2 has been accepted by ECCV2024.
-
2024-03-22: We present the InternVideo2 and the code is integrated into github.
-
2024-03-15: We present the suite of modeling video with mamba video-mamba-suite and release the code at github.
-
2024-02-27: 4 CVPR papers are accepted. They are InternVL for general visual understanding, MVBench for chat-centric video understanding, EgoInstructor for egocentric captioning and EgoExoLearn for ego-exo cross-view datasets and model suite. EgoExoLearn github repo.
-
2023-12-26: We present the generlist visual-language model InternVL and release the code at github.
-
2023-10-10: In the first Perception Test challenge, We obtain the best performance in Temporal Sound Localisation & runner-up in Temporal Action Localisation. The code of solution is here.
-
2023-05-22: We present a novel Video Sequence Understanding Framework VideoLLM.
-
2023-01-17: Our team wins the champion of WSDM Cup 2023 Toloka VQA Challenge.
-
2022-11-17: 🎂 We provide the final Ego4D report and the code.
-
2022-09-19: Our team wins Top-1 rankings in 7 tracks of Ego4D ECCV2022 Challenge.
-
2022-09-15: We have released the source code of BasicTAD.
-
2022-05-05: We present the BasicTAD, an end-to-end TAD baseline method.
📝 Publications

Eagle 2.5: Boosting long-context post-training for frontier vision-language models
Guo Chen, Zhiqi Li, Shihao Wang, Jindong Jiang, Yicheng Liu, Lidong Lu, De-An Huang, Wonmin Byeon, Matthieu Le, Tuomas Rintamaki, Tyler Poon, Max Ehrlich, Tuomas Rintamaki, Tyler Poon, Tong Lu, Limin Wang, Bryan Catanzaro, Jan Kautz, Andrew Tao, Zhiding Yu, Guilin Liu.
- This paper introduces Eagle 2.5, a generalist long-context VLM for videos and high-res images, combining Automatic Degrade Sampling, Image Area Preservation, and the Eagle-Video-110K dataset to reach 72.4% on Video-MME (512 frames), rivaling much larger models.
Eagle 2: Building Post-Training Data Strategies from Scratch for Frontier Vision-Language Models
Zhiqi Li, Guo Chen, Shilong Liu, Shihao Wang, Vibashan VS, Yishen Ji, Shiyi Lan, Hao Zhang, Yilin Zhao, Subhashree Radhakrishnan, Nadine Chang, Karan Sapra, Amala Sanjay Deshmukh, Tuomas Rintamaki, Matthieu Le, Ilia Karmanov, Lukas Voegtle, Philipp Fischer, De-An Huang, Timo Roman, Tong Lu, Jose M Alvarez, Bryan Catanzaro, Jan Kautz, Andrew Tao, Guilin Liu, Zhiding Yu
- This work focuses on developing open-source vision-language models by emphasizing data strategy in post-training, resulting in the performant Eagle2 models that achieve state-of-the-art results across various multimodal benchmarks.
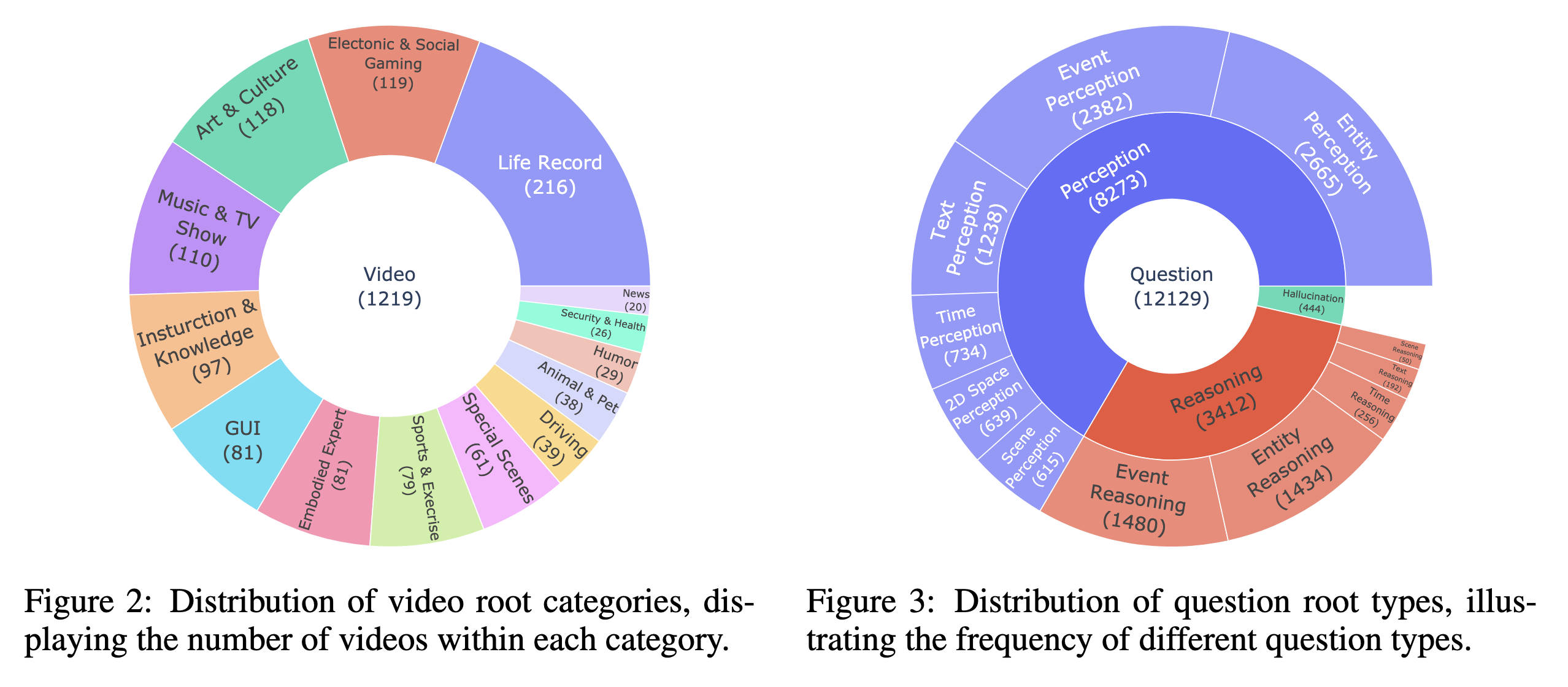
Cg-bench: Clue-grounded question answering benchmark for long video understanding
Guo Chen, Yicheng Liu, Yifei Huang, Yuping He, Baoqi Pei, Jilan Xu, Yali Wang, Tong Lu, Limin Wang
- CG-Bench tests multimodal models on long videos with clue-based QA, featuring 1,219 videos and 12,129 questions. It highlights challenges in video comprehension and the gap between open-source and commercial models.
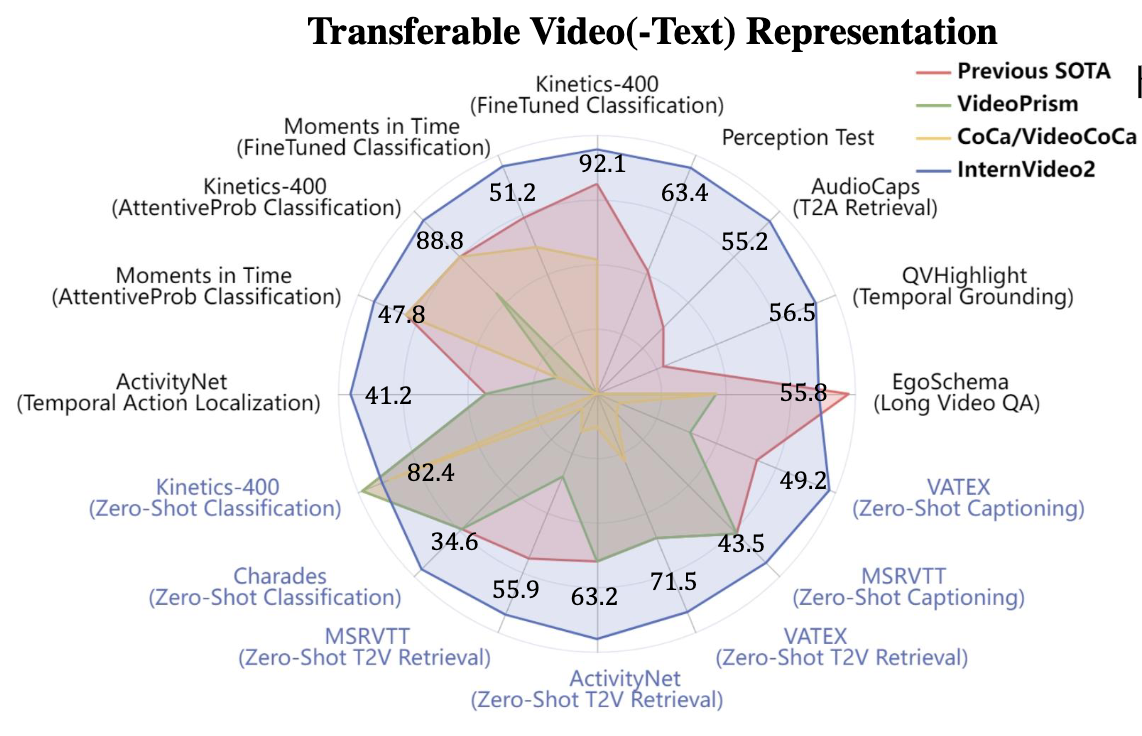
Internvideo2: Scaling foundation models for multimodal video understanding
Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Guo Chen, Baoqi Pei, Rongkun Zheng, Zun Wang, Yansong Shi, Tianxiang Jiang, Songze Li, Jilan Xu, Hongjie Zhang, Yifei Huang, Yu Qiao, Yali Wang, Limin Wang
- InternVideo2 offers advanced video models with a 6B encoder, excelling in video recognition, text alignment, and dialogue, achieving top results in over 60 tasks.

Yifei Huang, Guo Chen, Jilan Xu, Mingfang Zhang, Lijin Yang, Baoqi Pei, Hongjie Zhang, Lu Dong, Yali Wang, Limin Wang, Yu Qiao
- EgoExoLearn is a dataset with 120 hours of egocentric and demonstration videos, gaze data, and multimodal annotations, designed to advance AI learning through observation and cross-view task benchmarks.
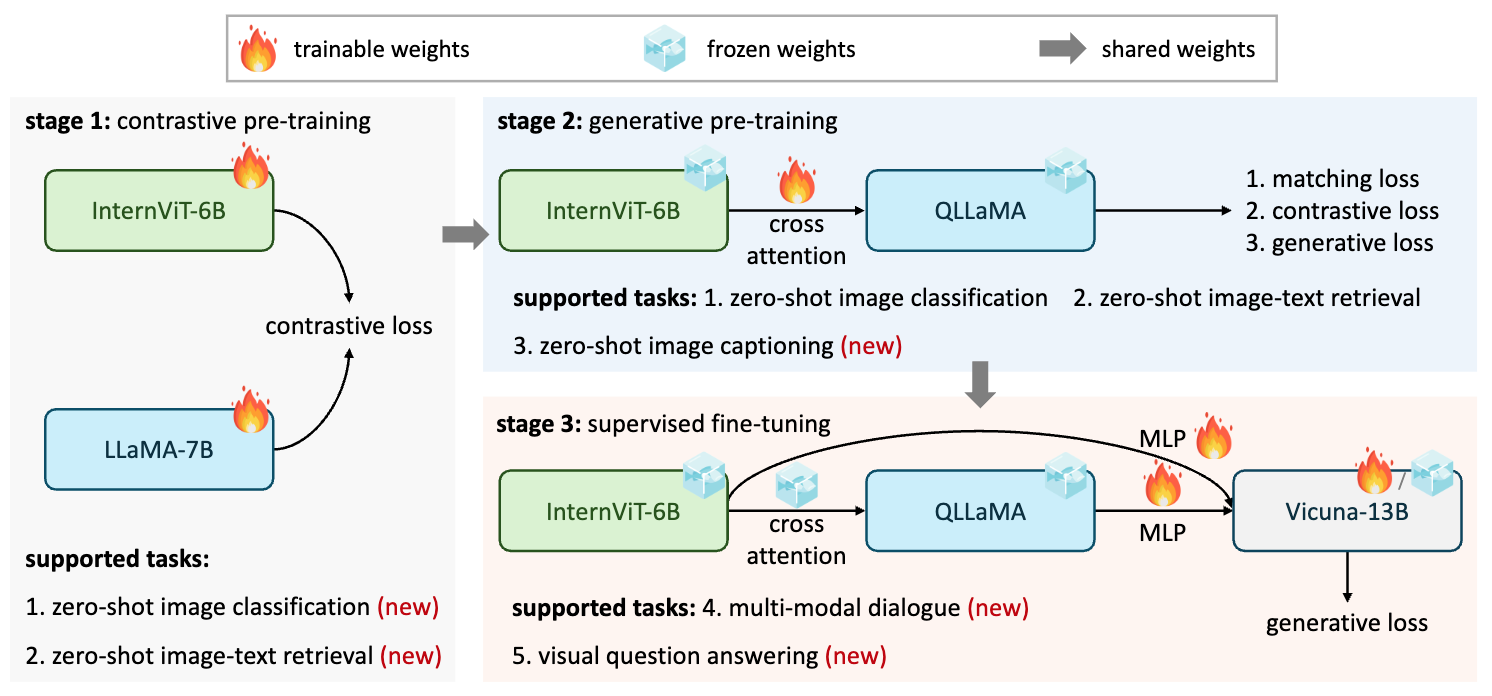
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, Jifeng Dai#
- We developed InternVL, a 6 billion parameter vision-language model, aligned with large language models using vast image-text data. It achieves state-of-the-art results on 32 benchmarks, advancing multi-modal AGI.
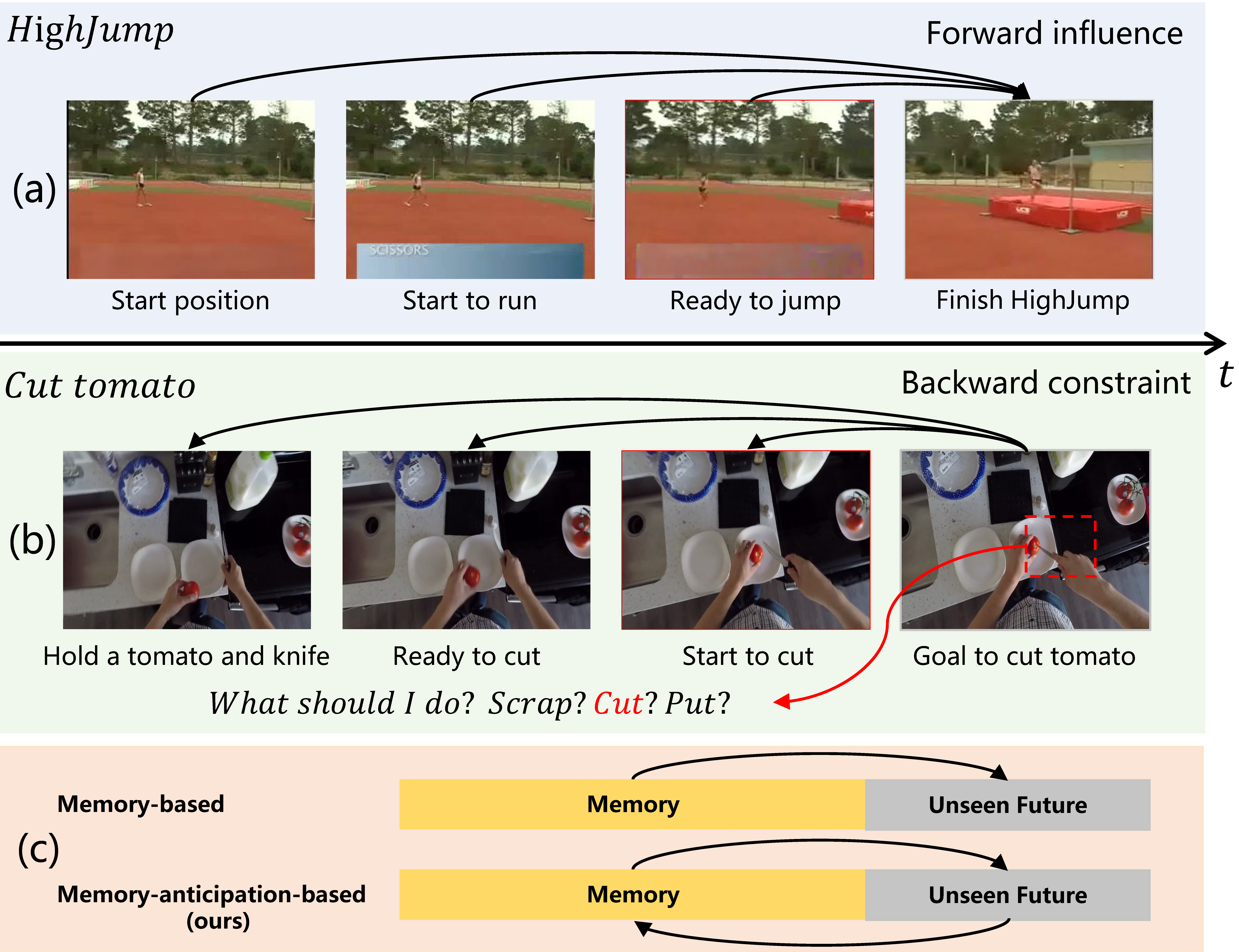
Memory-and-Anticipation Transformer for Online Action Understanding
Jiahao Wang*, Guo Chen, Yifei Huang, Limin Wang, Tong Lu#
- This work presents a memory-anticipation-based method for online action understanding.

BasicTAD: an Astounding RGB-Only Baseline for Temporal Action Detection
Min Yang, Guo Chen, Yin-Dong Zheng, Tong Lu, Limin Wang#
- This work presents a simple yet effective end-to-end training framework for temporal action detection.

DCAN: Improving Temporal Action Detection via Dual Context Aggregation
Guo Chen, Yin-Dong Zheng, Limin Wang, Tong Lu#
- This work explored boundary-based methods for temporal action detection and proposed a novel network, termed DCAN, to improve temporal action detection via temporal-level and proposal-level context aggregation.
- Egoexobench: A benchmark for first-and third-person view video understanding in mllms, Yuping He, Yifei Huang, Guo Chen, etal. NIPS 2025
- Vinci: A Real-time Smart Assistant Based on Egocentric Vision-language Model for Portable Devices, Yifei Huang, Jilan Xu, Baoqi Pei, Lijin Yang, Mingfang Zhang, Yuping He, Guo Chen, etal. IMWUT 2025
- Egocentric Object-Interaction Anticipation with Retentive and Predictive Learning, Guo Chen, Yifei Huang, etal. IJCAI 2025
- Modeling Fine-Grained Hand-Object Dynamics for Egocentric Video Representation Learning, Baoqi Pei, Yifei Huang, Jilan Xu, Guo Chen, etal. ICLR 2025
- X-Gen: Ego-centric Video Prediction by Watching Exo-centric Videos, Jilan Xu, Yifei Huang, Baoqi Pei, Junlin Hou, Qingqiu Li, Guo Chen, etal. ICLR 2025
- Avsegformer: Audio-visual segmentation with transformer, Shengyi Gao, Zhe Chen, Guo Chen, etal. AAAI 2024
- Mvbench: A comprehensive multi-modal video understanding benchmark, Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, etal. CVPR 2024
- Retrieval-augmented egocentric video captioning, Jilan Xu, Yifei Huang, Junlin Hou, Guo Chen, etal. CVPR 2024
- Guiding Audio-Visual Question Answering with Collective Question Reasoning, Baoqi Pei, Yifei Huang, Guo Chen, etal. IJCV
- Internvid: A large-scale video-text dataset for multimodal understanding and generation, Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, etal. ICLR 2023
- Elan: Enhancing temporal action detection with location awareness, Guo Chen, Yin-Dong Zheng, etal. ICME 2023
- Mrsn: Multi-relation support network for video action detection, Yin-Dong Zheng, Guo Chen, etal. ICME 2023
- Matching compound prototypes for few-shot action recognition, Yifei Huang, Lijin Yang, Guo Chen, etal. IJCV
- Feature matters: Revisiting channel attention for Temporal Action Detection, Guo Chen, etal. PR
- Bridging Perspectives: A Survey on Cross-view Collaborative Intelligence with Egocentric-Exocentric Vision, Yuping He, Yifei Huang, Guo Chen, etal. Arxiv
- Videollm: Modeling video sequence with large language models, Guo Chen, Yin-Dong Zheng, Jiahao Wang, etal. Arxiv
- AV-Reasoner: Improving and Benchmarking Clue-Grounded Audio-Visual Counting for MLLMs, Lidong Lu, Guo Chen, etal. Arxiv
- VideoITG: Multimodal Video Understanding with Instructed Temporal Grounding, Shihao Wang, Guo Chen, etal. Arxiv
- Token-Efficient Long Video Understanding for Multimodal LLMs, Jindong Jiang, Xiuyu Li, Zhijian Liu, Muyang Li, Guo Chen, etal. Arxiv
- Video mamba suite: State space model as a versatile alternative for video understanding, Guo Chen, Yifei Huang, Jilan Xu, etal. Arxiv
- FAST: Faster Arbitrarily-Shaped Text Detector with Minimalist Kernel Representation, Zhe Chen, Jiahao Wang, Wenhai Wang, Guo Chen, etal. Arxiv
📝 Projects
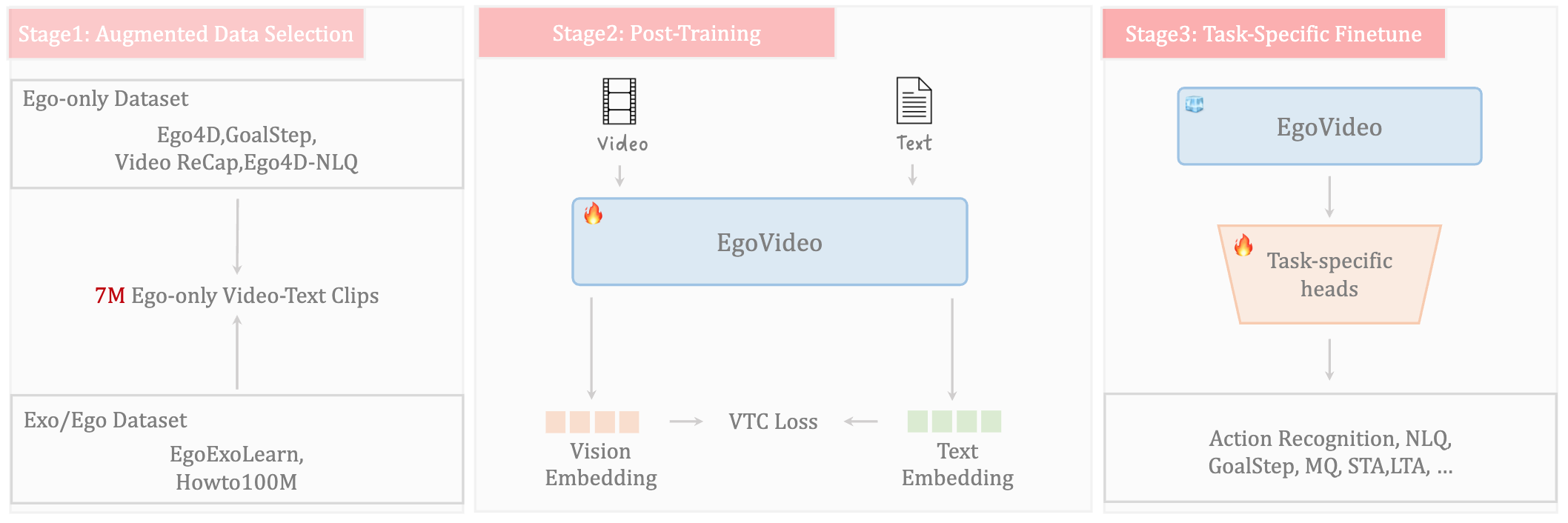
Egovideo: Exploring egocentric foundation model and downstream adaptation
Guo Chen, Baoqi Pei, Jilan Xu, Yuping He, Yicheng Liu, Kanghua Pan, Yifei Huang, Yali Wang, Tong Lu, Limin Wang, Yu Qiao
- This work presents our champion solutions to seven tracks at 1st EgoVis challenge.
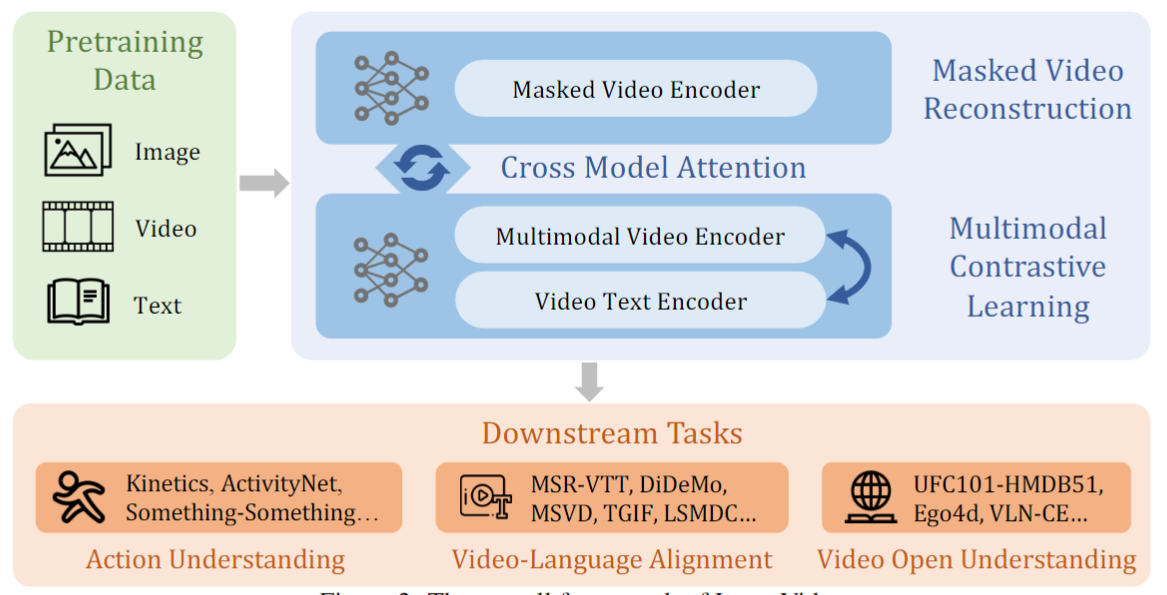
InternVideo: General Video Foundation Models via Generative and Discriminative Learning
Yi Wang, Kunchang Li, Yizhuo Li, Yinan He, Bingkun Huang, Zhiyu Zhao, Hongjie Zhang, Jilan Xu, Yi Liu, Zun Wang, Sen Xing, Guo Chen, Junting Pan, Jiashuo Yu, Yali Wang, Limin Wang, Yu Qiao#
- This work presents our champion solutions to seven tracks at Ego4D challenge.
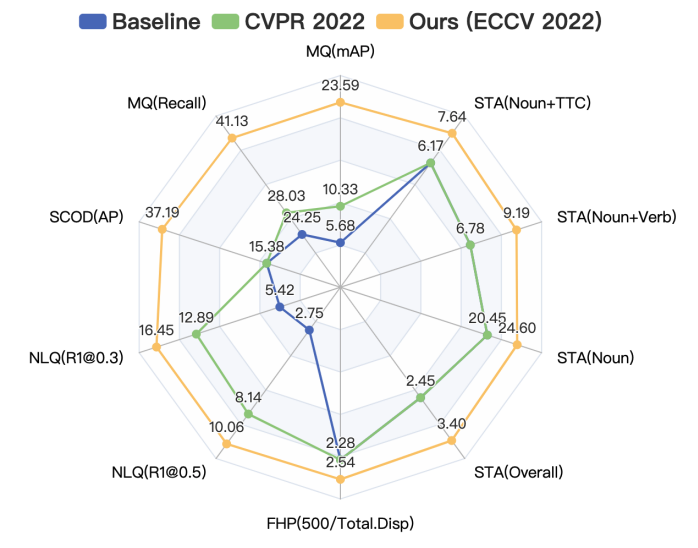
InternVideo-Ego4D: A Pack of Champion Solutions to Ego4D Challenges
Guo Chen, Sen Xing, Zhe Chen, Yi Wang, Kunchang Li, Yizhuo Li, Yi Liu, Jiahao Wang, Yin-Dong Zheng, Bingkun Huang, Zhiyu Zhao, Junting Pan, Yifei Huang, Zun Wang, Jiashuo Yu, Yinan He, Hongjie Zhang, Tong Lu, Yali Wang, Limin Wang, Yu Qiao#
- This work presents our champion solutions to five tracks at Ego4D challenge.
🎖 Honors and Awards
- 2025-05-29: Egocentric Vision (EgoVis) 2023/2024, CVPR2025, Distinguished Paper Award
- 2024-07-01: 1st EgoVis Challenge, ECCV2024, 7 Top-1 Rankings
- 2023-10-01: 1st Perception Test Challenge, Top-1 and Top-2 Rankings
- 2023-01-01: WSDM Cup 2023 Toloka VQA Challenge, WSDM2023, Top-1 Ranking
- 2022-10-01: 2nd Ego4D Challenge, ECCV2022, 7 Top-1 Rankings
- 2017-12-01: CCPC Final Contest, Bronze Medal
- 2017-10-01: CCPC Regional Contest, Bronze Medal
- 2017-10-15: ACM-ICPC Asia Regional Contest, Silver Medal
🔍 Academic Services
Conference Reviewer: NeurIPS, ICLR, CVPR, ICCV, ECCV, AAAI, ACM MM, IJCAI
Journal Reviewer: IJCV, CVIU, PR
📖 Educations
- 20.09 - present, Nanjing University, Nanjing, China
- 15.09 - 19.06, University of South China, Hengyang, China